Wenn man es genau wissen will …
… schnappt man sich das Congruence-Association Model (CAM-WN) von A.J. Cohen. Ursprünglich für die Frage entwickelt, welche Rolle der Musik im Film zukommt, eignet sich das Modell fantastisch auch für Erfahrungsarchitekturen in ganz anderen Bereichen.
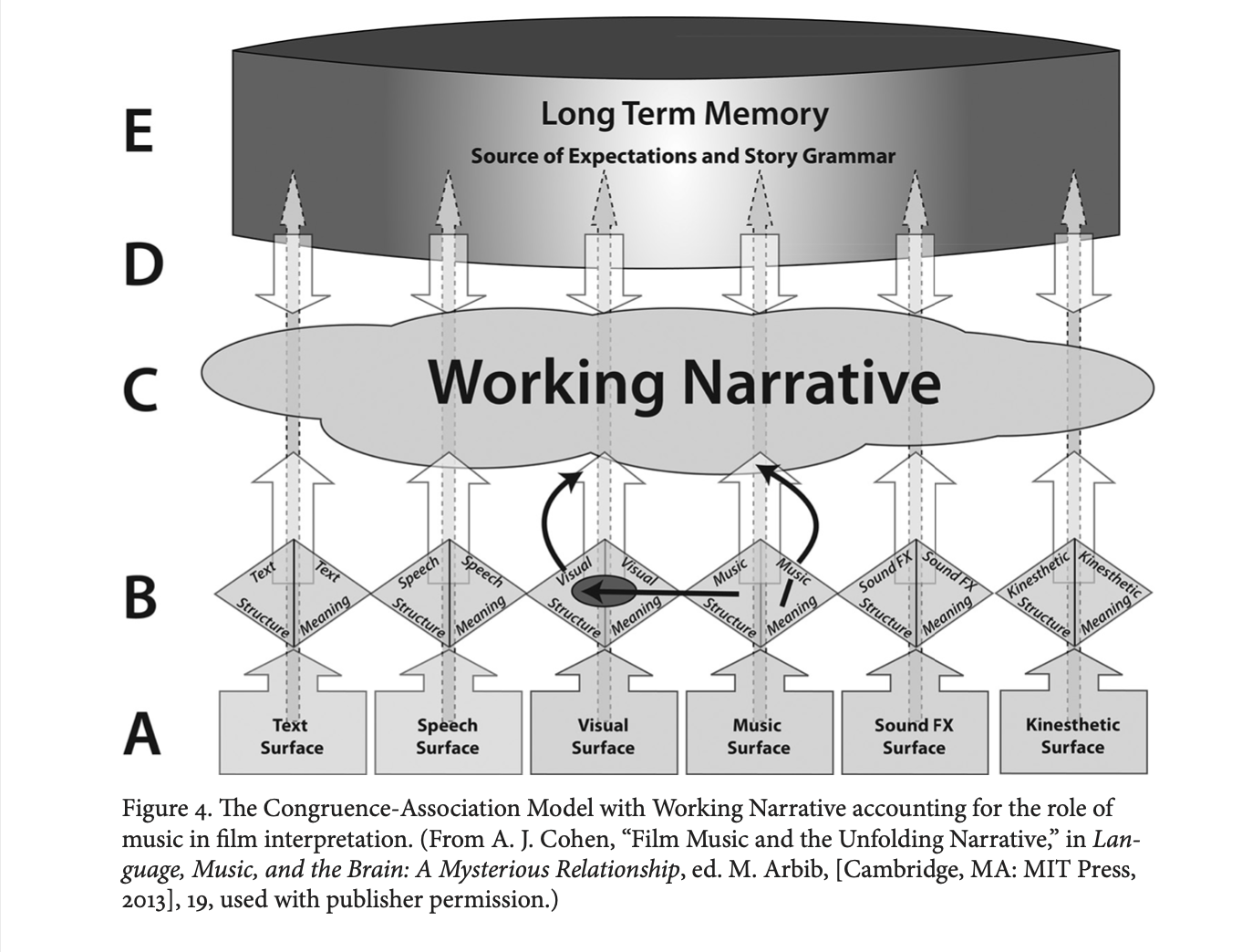
Wie funktioniert das Modell?
In short: Auf Ebene C befindet sich das Narrativ – also die Form der Darstellung bzw. die Erzählung. Ein Film, ein Bild, eine Intervention… Ebene A stellt die jeweiligen Informationsebenen dar aus denen das Narrativ besteht. Bei einem Film wären dies Musik, Bild, Soundeffekte, Text und Sprache. Ebene E steht für das Langzeitgedächtnis des Rezipienten. Hier sammeln sich unsere bisherigen Erfahrungen und wir leiten darauf basierend unbewusst unser Handeln und unsere Erwartungen an die weitere Handlung ab. Die Pfeile zwischen den Ebenen bilden die entstehende Dynamik ab und lassen sich wie folgt lesen: Der dünne, gestrichelte Pfeil von Ebene A nach E steht für das unbewusste Aufnehmen, Abgleiche und Interpretieren der jeweiligen Information in unserem Gehirn. So sehen wir z.B. eine Person auf der Straße gehen und erwarten, dass sie sich „ungefähr durchschnittlich“ verhält, was bedeuten kann, dass sie weder übertrieben schnell noch übertrieben langsam geht. Weder auf einen Punkt starrt, noch durchgehend nach oben blickt. Wir weben ein feines Erwartungsnetz auf die Welt, in dem Handlungen oftmals erst auffallen, wenn sie diesem nicht entsprechen. Die Pfeile zwischen D und C stehen für diese, meist unbewussten Ableitungen, die wir beim Rezipieren des „Working Narratives“ anstellen. Die Pfeile zwischen B und C hingegen stellen die bewussten Interpretationen dar, die durch die Inputs auf Ebene A ausgelöst werden. Wir interpretieren das Gesehene, Gehörte, Gefühlte dabei subjektiv sowohl nach Struktur als auch nach deren semantisch-assoziativer Bedeutung.
Zusammenfassend also ein spannender Ansatz, um Erfahrungen zu planen oder aber auch in Nachhinein zu analysieren. Mehr dazu findet sich auch im Buch „The Psychology of Music in Multimedia“, Siu-Lan Tan Annabel J. Cohen Scott D. Lipscomb and
Roger A. Kendall, Oxford University Press, 2013.